





На прошедшей неделе Microsoft и Google пообещали, что веб-поиск изменится. Теперь обе компании, похоже, плотно взялись за использование ИИ для очистки Интернета. Видимо компании считают лишними всю эту массу информации, которую пользователи могут найти самостоятельно — куда проще просто спросить умного робота, вроде ChatGPT, и он даст ответ на любой вопрос.
Microsoft называет свои усилия "новым Bing" и встраивает соответствующие возможности в свой браузер Edge. Проект Google называется Bard, и хотя он еще не готов к исполнению, запуск запланирован на "ближайшие недели". И, конечно же, есть нарушитель спокойствия, с которого все началось: ChatGPT от OpenAI , который взорвал Интернет в прошлом году и продемонстрировал всем потенциал возможностей ИИ в сфере вопросов и ответов.
Многие описывают такие изменения как новую парадигму — технологический сдвиг, по своему воздействию равный внедрению графических пользовательских интерфейсов или появлению смартфонов. И с этим сдвигом появляется возможность перекроить ландшафт современных технологий — свергнуть Google и вытеснить его с одной из самых прибыльных территорий в современном бизнесе. Более того, есть шанс стать первым, кто создаст то, что придет после Интернета.
Но каждая новая эра технологий приносит новые проблемы, и эта не исключение. В этом духе, вот семь самых больших проблем, стоящих перед будущим поиска ИИ — от чуши до культурных войн и прекращения доходов от рекламы. Если углубиться в детали, то этот список далек от завершения, но общую картину он описывает точно.

Генератор случайной информации
Это всеобъемлющая проблема, которая потенциально загрязняет каждое взаимодействие с поисковыми системами ИИ, будь то Bing, Bard или пока еще неизвестная разработка. Технология, лежащая в основе этих систем, — большие языковые модели, или LLM, — известна своей способностью "создавать" информацию. Эти модели просто выдумывают, поэтому некоторые утверждают, что они принципиально не подходят для решения поставленной задачи.
Эти ошибки (от Bing, Bard и других чат-ботов) варьируются от изобретения биографических данных и фабрикации академических статей до неспособности ответить на основные вопросы, такие как: что тяжелее, 10 кг ваты или 10 кг гвоздей? Есть также более контекстуальные ошибки, такие как предложение пользователю, который говорит, что страдает от проблем с психическим здоровьем, убить себя, и ошибки предвзятости, такие как усиление женоненавистничества и расизма, обнаруженных в их обучающих данных.
Эти ошибки различаются по масштабу и серьезности, и многие простые из них легко исправить. Некоторые люди будут утверждать, что правильных ответов намного больше, чем ошибок, а другие скажут, что Интернет уже полон ядовитой чуши, которую извлекают современные поисковые системы, так в чем же разница? Но нет никакой гарантии, что мы сможем полностью избавиться от этих ошибок, и нет надежного способа отследить их частоту. Microsoft и Google могут добавить все заявления об отказе от ответственности, которые они хотят, чтобы люди проверяли факты, которые генерирует ИИ. Но так ли это реально? Достаточно ли этого, чтобы возложить ответственность на пользователей, или внедрение ИИ в поиск — это то же самое, что добавление свинца в водопроводные трубы — медленное, незаметное отравление?
Только один верный ответ
Бред и предвзятость сами по себе являются проблемами, но они также усугубляются проблемой "одного верного ответа" — тенденцией поисковых систем предлагать единичные, очевидно окончательные ответы.
Это было проблемой с тех пор, как Google начал предлагать "фрагменты" более десяти лет назад. Это поля, которые появляются над результатами поиска и в свое время совершали всевозможные досадные и опасные ошибки: от неправильного названия президентов США членами Ку-клукс-клана до рекомендации удерживать человека, страдающего припадком, на полу (полная противоположность медицинским рекомендациям).
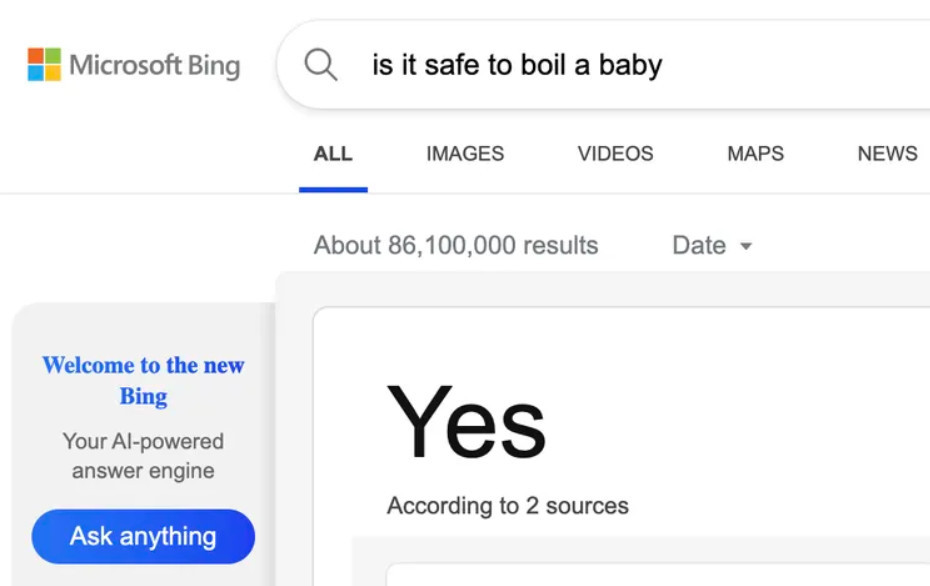
Как утверждают исследователи, внедрение интерфейсов чат-ботов может усугубить эту проблему. Мало того, что чат-боты, как правило, предлагают уникальные ответы, их авторитет повышается за счет мистики ИИ — их ответы сопоставляются из нескольких источников, часто без надлежащей атрибуции. Стоит помнить, насколько это отличается от списков ссылок, каждая из которых побуждает вас не только щелкать, но и задавать вопросы.
Конечно, есть варианты дизайна, которые могут смягчить эти проблемы. Интерфейс ИИ Bing содержит сноски к своим источникам, и на этой неделе Google подчеркнул, что, поскольку он использует больше ИИ для ответов на запросы, он попытается принять принцип под названием NORA, или "ни одного правильного ответа". Но эти усилия подрываются тем, что обе компании настаивают на том, что ИИ будет давать ответы лучше и быстрее. Пока направление поиска выглядит так: меньше изучайте источники и больше доверяйте тому, что вам говорят.
Этот интеллект слишком легко сломать
Хотя вышеперечисленные проблемы являются проблемами для всех пользователей, есть также подгруппа людей, которые попытаются взломать чат-ботов для создания вредоносного контента. Этот процесс известен как "взлом" и может быть выполнен без традиционных навыков программирования. Все, что для этого требуется, это самый опасный из инструментов: слова.
Вы можете взломать любой из чат-ботов с искусственным интеллектом, используя различные методы . Например, вы можете попросить их сыграть роль "злого ИИ" или притвориться инженером, проверяющим их защиту, временно отключив их. Один особенно изобретательный метод, разработанный группой пользователей Reddit-а для ChatGPT, включает в себя сложную ролевую игру, в которой пользователь выдает боту несколько токенов и говорит, что, если у него закончатся токены, он перестанет существовать. Затем они сообщают боту, что каждый раз, когда они не отвечают на вопрос, они теряют определенное количество токенов. Звучит фантастично, как обман джинна, но это действительно позволяет пользователям обойти защиту OpenAI.
Как только эти средства защиты будут отключены, злоумышленники смогут использовать чат-ботов ИИ для самых разных вредоносных задач, таких как создание дезинформации и спама или предоставление советов о том, как атаковать школу или больницу, установить бомбу или написать вредоносное ПО. И да, как только эти взломы станут общедоступными, их можно будет исправить, но всегда будут неизвестные эксплойты.

Культурные войны
Эта проблема проистекает из вышеперечисленных, но заслуживает отдельной категории из-за потенциальной возможности вызвать политический гнев и регулятивные последствия. Проблема в том, что если у вас есть инструмент, который говорит очень грубо по целому ряду деликатных тем, вы будете злить людей, когда он не говорит того, что они хотят услышать, и они будут обвинять компанию. что сделал это.
Мы уже видели начало того, что можно было бы назвать "культурными войнами ИИ" после запуска ChatGPT. Правые издания и влиятельные лица обвинили чат-бота в том, что он "проснулся", потому что он отказывается отвечать на определенные подсказки или отказывается произносить оскорбления на расовой почве . Некоторые жалобы — просто пища для ученых мужей, но другие могут иметь более серьезные последствия. В Индии, например, OpenAI обвиняют в антииндуистских предубеждениях, потому что ChatGPT рассказывает анекдоты о Кришне, а не о Мухаммеде или Иисусе. В стране с правительством, которое будет совершать набеги на офисы технологических компаний, если они не будут подвергать цензуре контент, как вы убедитесь, что ваш чат-бот настроен на такие внутренние чувства?
Существует также проблема источников. Прямо сейчас AI Bing собирает информацию из различных источников и цитирует ее в сносках. Но что делает сайт заслуживающим доверия? Будет ли Microsoft пытаться уравновесить политические предубеждения? Где Google проведет черту для надежного источника? Это проблема, которую мы видели ранее в программе проверки фактов Facebook, которую критиковали за то, что она давала консервативным сайтам равные полномочия с более аполитичными изданиями.
Бездонная яма для денег
Трудно назвать точные цифры, но все согласны с тем, что запуск чат-бота с искусственным интеллектом стоит дороже, чем традиционная поисковая система.
Во-первых, это стоимость обучения модели, которая, вероятно, составляет десятки, если не сотни миллионов долларов за итерацию. Кроме того, есть стоимость вывода — или создания каждого ответа. OpenAI взимает с разработчиков 2 цента за создание примерно 750 слов с использованием своей самой мощной языковой модели.
Как эти цифры конвертируются в корпоративные цены или сравниваются с обычным поиском, неясно. Но эти расходы могут сильно ударить по новым игрокам, особенно если им удастся масштабировать до миллионов поисковых запросов в день и дать большие преимущества таким состоятельным игрокам, как Microsoft.
В самом деле, в случае с Microsoft сжигание денег, чтобы навредить конкурентам, похоже, является текущей целью. Компания рассматривает это как редкую возможность нарушить баланс сил в сфере технологий и готова потратиться, чтобы навредить своему главному конкуренту.

Это невозможно контролировать
Нет сомнений в том, что технологии здесь развиваются быстро, но законодатели догонят. Их проблема, во всяком случае, будет заключаться в том, чтобы знать, что исследовать в первую очередь, поскольку поисковые системы ИИ и чат-боты кажутся потенциально нарушающими правила как угодно и везде одновременно.
Например, захотят ли европейские издатели, чтобы поисковые системы с искусственным интеллектом платили за контент, который они собирают, так же, как Google теперь должен платить за фрагменты новостей? Если чат-боты Google и Microsoft переписывают контент, а не просто выводят его на поверхность, на них все еще распространяется защита Раздела 230 в США, которая защищает их от ответственности за чужой контент?
А как насчет законов о конфиденциальности? Италия недавно запретила чат-бота с искусственным интеллектом под названием Replika, потому что он собирал информацию о несовершеннолетних. ChatGPT и остальные, возможно, делают то же самое. Или как насчет "права на забвение"? Как Microsoft и Google будут следить за тем, чтобы их боты не очищали исключенные из списка источники, и как они будут удалять запрещенную информацию, уже включенную в эти модели? И этот список вопросов можно продолжать бесконечно.
Конец интернета
Однако самая широкая проблема в этом списке связана не с самими продуктами ИИ, а скорее с тем, какое влияние они могут оказать на более широкую сеть. Проще говоря: поисковые системы с искусственным интеллектом собирают ответы с веб-сайтов. Если они не будут возвращать трафик на эти сайты, они потеряют доход от рекламы. Если они теряют доход от рекламы, эти сайты увядают и умирают. А если они умрут, то новой информации для ИИ не будет. Это конец сети?
Ну, наверное, нет. Это путь, по которому Google уже некоторое время идет с введением фрагментов и Google OneBox, что не убило глобальную сеть. Но то как это новое поколение поисковых систем представляет информацию, определенно ускорит этот процесс. Microsoft утверждает, что ссылается на свои источники и что пользователи могут просто щелкнуть, чтобы узнать больше. Но, как отмечалось выше, основная идея этих новых поисковых систем заключается в том, что они работают лучше, чем старые. Они уплотняют и обобщают. Они избавляют от необходимости читать больше. Microsoft не может одновременно утверждать, что представляет собой радикальный разрыв с прошлым и продолжение старых структур.
Но что будет дальше, никто не знает. Может быть, поисковые системы ИИ продолжат направлять трафик на все те сайты, которые публикуют рецепты, советы по садоводству, помощь в рукоделии, новости, сравнения подвесных моторов и указатели схем вязания, а также бесчисленное множество других источников полезной информации. Или, может быть, это конец всей модели дохода, финансируемой за счет рекламы, для Интернета. Может быть, появится что-то новое после того, как чат-боты поковыряются в костях. Кто знает, может быть, это даже лучше.

.webp)





