

Процесс обучения современный нейронных сетей в последнее время подвержен заметному замедлению, ввиду снижения темпов роста общей производительности компьютеров. Нарушение закона Мура заставляет учёных искать новые подходы к обучению. Как следствие — поиск совершенно нового способа организации и построении сами нейронных сетей. Одним из вариантов решения было использование квантовых вычислений и операций с кубитами, но готовых структурных решений для подобных нейросетей не было. До настоящего момента.
Команда учёных из Ганноверского университета имени Лейбница под руководством профессора Рамоны Вульф смогли спроектировать квантовый аналог классической модели нейрон, который образуют нейросеть пригодную для выполнения квантовых вычислений. Статья посвящённая их работе опубликована в Nature Communications.
Сеть, разработанная учёными, позволяет производить универсальные квантовые вычисления, при том значительно сокращая число кубитов используемых для хранения промежуточных результатов. Элементарным блоком квантовой нейросети являются квантовые перцептроны, прямые аналоги перцептронов классических сетей. В качестве вводных данных используется исходное состояние кубитов, а предсказанием (результатом) выходное их состояние.
Процесс обучения квантовой нейросети несколько сложнее классических аналогов. Для успешной реализации необходимо вести метрику потереть, которые в дальнейшем минимизируются. Из-за особенностей кубитов процесс сбора и анализа потерь необходимо повторять многократно, для достижения оптимального результата. Несмотря на высокое быстродействие современных квантовых компьютеров, объём данных, накапливающихся в ходе процесса перезапуска крайне велик.
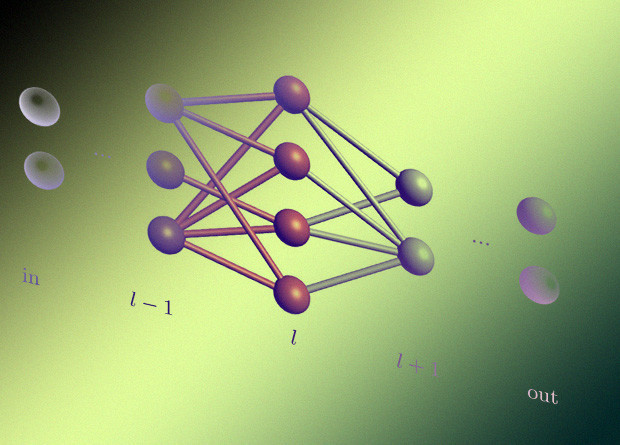
Эту проблему решает одна из основных особенностей предложенного командой Рамоны Вульф метода обучения. Его суть состоит в том, что параметры локальных преобразований могут быть вычислены послойно, без необходимости применения преобразования ко всем кубитам. Как следствие количество изменяемых параметров масштабируется лишь с шириной сети, что позволяет обучать очень глубокие нейросети.
В таком процессе обучения значительно сокращается число кубитов, необходимых для хранения промежуточных состояний, которые нужны для предсказаний, а значит и постоянные перезапуске системы будут происходить значительно быстрее, отнимая минимум производительности.






