Системы, предназначенные для обнаружения дипфейков — видео, которые манипулируют реальными кадрами с помощью искусственного интеллекта, — могут быть обмануты, как впервые показали компьютерные ученые на конференции WACV 2021, которая проходила онлайн с 5 по 9 января 2021 года.
Исследователи показали, что детекторы можно обойти, вставляя входные данные, называемые состязательными примерами, в каждый видеокадр. Состязательные примеры — это слегка измененные входные данные, которые заставляют системы искусственного интеллекта, такие как модели машинного обучения, допускать ошибку. Кроме того, команда показала, что эффект все еще работает после сжатия видео.
Шехзин Хуссейн, доктор компьютерных наук Калифорнийского университета в Сан-Диего, первый соавтор работы, сказал:
Наша работа показывает, что атаки на детекторы дипфейков могут быть реальной угрозой. Что еще более тревожно, мы демонстрируем, что можно создавать надежные состязательные дипфейки, даже если противник может не знать о внутренней работе модели машинного обучения, используемой детектором.
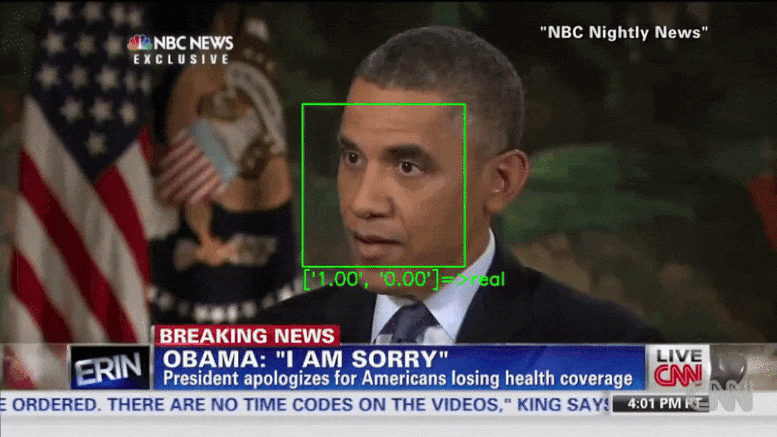
В дипфейках лицо объекта модифицируется, чтобы создать убедительно реалистичные кадры событий, которых на самом деле никогда не было. В результате типичные детекторы дипфейков фокусируются на лице в видео: сначала отслеживают его, а затем передают данные обрезанного лица в нейронную сеть, которая определяет, настоящее оно или фальшивое. Например, моргание не воспроизводится в дипфейках, поэтому детекторы фокусируются на движениях глаз как на одном из способов сделать это определение. Современные детекторы Deepfake полагаются на модели машинного обучения для выявления поддельных видео.
Исследователи отмечают, что широкое распространение поддельных видеороликов через платформы социальных сетей вызвало серьезную обеспокоенность во всем мире, особенно подрывая доверие к цифровым медиа.
Исследователи создали состязательный пример для каждого лица в кадре видео. Но в то время как стандартные операции, такие как сжатие и изменение размера видео, обычно удаляют из изображения враждебные примеры, эти примеры созданы, чтобы противостоять этим процессам. Алгоритм атаки делает это, оценивая набор входных преобразований, как модель оценивает изображения как настоящие или поддельные. Оттуда он использует эту оценку для преобразования изображений таким образом, чтобы состязательное изображение оставалось эффективным даже после сжатия и распаковки.
Затем измененная версия лица вставляется во все видеокадры. Затем процесс повторяется для всех кадров видео, чтобы создать видео Deepfake. Атака также может быть применена к детекторам, которые работают с целыми видеокадрами, а не только с обрезками лиц. Команда отказалась выпустить свой код, чтобы его не использовали враждебные стороны.
Высокая вероятность успеха
Исследователи протестировали свои атаки в двух сценариях: в первом, когда злоумышленники имеют полный доступ к модели детектора, включая конвейер извлечения лиц, а также архитектуру и параметры модели классификации; и тот, где злоумышленники могут запрашивать модель машинного обучения только для определения вероятности того, что кадр будет классифицирован как настоящий или поддельный.
В первом сценарии вероятность успеха атаки для несжатых видео превышает 99 процентов. Для сжатых видео — 84,96%. Во втором сценарии коэффициент успеха составил 86,43% для несжатого видео и 78,33% для сжатого видео. Это первая работа, демонстрирующая успешные атаки на современные детекторы Deepfake.
Для улучшения детекторов исследователи рекомендуют подход, аналогичный так называемому состязательному обучению: во время обучения адаптивный противник продолжает генерировать новые дипфейки, которые могут обойти современный детектор; и детектор продолжает совершенствоваться, чтобы обнаруживать новые дипфейки.